На пути к вычислению правильно округлённого значения гипотенузы
Пытаясь сделать вариант hypot(x, y), вычисляющий правильно округлённый результат для всех пар чисел x и y, я обнаружил, что используемая для проверки hypot_v3 может быть вовсе не так хороша, как я полагал.
В первой заметке я написал, что она обеспечивает погрешность <= 0.5 ULP, что неточно, так как происходит два округления: при вычислении корня в формате double и затем при конвертировании double во float. Технически погрешность <= 0.5 * (1 + DBL_EPSILON) ULP, эта маленькая добавка (DBL_EPSILON == 2.22045e-16) теоретически может сказаться в редких случаях.
Приведу некоторые очевидные свойства hypot(x, y):
1. Коммутативность: hypot(x, y) == hypot(y, x).
2. Чётность: hypot(-x, y) == hypot(x, -y) == hypot(x, y).
3. Округление: если |x| + |y| == max(|x|, |y|), то hypot(x, y) == max(|x|, |y|).
Данные свойства позволяют оценить количество "разных" пар x, y, дающих нетривиальный результат.
Всего имеется неотрицательных чисел float: 255·223 = 2139095040 (включая +бесконечность). Из них субнормальных 223-1 = 8388607 (с нулём), нормальных — 2130706433. Для субнормальных имеем 8388607·4194303 = 35184359505921 комбинаций. Для нормальных — 2130706433·224 = 35747322059030528 комбинаций. Всего 35782506418536449 ≈ 3.58e+16 комбинаций. Если считать, что DBL_EPSILON является хорошей оценкой вероятности ошибки, то умножив её на число комбинаций получим округлённо 8 — матожидание числа неверно округлённых пар. Считанные единицы, на которые можно надеяться натолкнуться только при переборе хотя бы одной восьмой всех возможных сочетаний значений x и y…
Увы, на практике всё несколько хуже. Для нормальных чисел. И много-много хуже для субнормальных! Действительно, оценка погрешности предполагает нормальную форму числа, при которой ULP имеет фиксированный (в относительной погрешности) вес (2-23). В субнормальных числах последняя цифра имеет больший вес вплоть до 100% (когда это единственная единица — в наименьшем представимом положительном числе). Исходя из этого наблюдения, можно попробовать добавить в hypot_v3 коррекцию порядка:
inline float hypot_v3a(float x, float y)
{
const double x_ = x, y_ = y,
s = x_ * x_ + y_ * y_;
if (s >= 0x1p-251)
return (float)std::sqrt(s);
return 0x1p-126f * (float)std::sqrt(0x1p+252 * s);
}
Эта небольшая поправка вроде бы вообще не должна влиять на цифры множителя, однако на практике резко уменьшает число дефектных результатов в субнормальной области (на момент написания я не наткнулся ни на одну подозрительную пару из субнормальных чисел). Среди нормальных подозрение вызывают, например, пары (0.0003162f, 1.661635309e-7f), (0.01f, 0.0001590774482f) и (1e+15f, 4.605317338e+15f).
Итак, я заменил проверочную hypot_v3 на hypot_v3a. Мы знаем, что результат sqrt(x*x + y*y) после коррекции порядка отличается от правильно округлённой гипотенузы не более, чем на вес последней цифры. Здесь надо сделать замечание по поводу того, что именно я под этим подразумеваю. Представление чисел в формате IEEE-754 обладает удобным свойством: их побитовым представлением можно оперировать как целым числом. В случае float 22 младших бита есть двоичные цифры множителя после запятой. Перед запятой подразумевается 1, если число нормальное, и 0, если субнормальное. За 22 битами цифр следует 8 бит порядка. Значение порядка 0 соответствует нулю и субнормальным числам. Значения 1—254 соответствуют нормальным числам (множители от 2-126 до 2127). Порядок 255 соответствует бесконечности (нулевые младшие 22 бита) и нечислам (ненулевые).
В моём случае получается, что модуль разности результата hypot_3a и результата вычисления корня одинарной точности, интерпретируемых как целые числа в соответствии с их двоичным представлением, не превосходит единицы. А значит, получив неточный результат z, я могу рассмотреть два соседних числа, добавив или вычтя 1 из двоичного представления z как из целого числа (то же, что std::nextafter(z, INFINITY), std::nextafter(z, 0.f), но стандартная реализация nextafter тоже не блещет скоростью — она предполагает обработку различных случаев, которых у меня не может быть). Итак, если удастся оценить погрешность результата, то помимо вычисленного значения должно быть достаточно проверить следующее (добавить единицу как к целому) и предыдущее (вычесть единицу как из целого) числа — какое-то из них может оказаться правильным ответом.
В начале, впрочем, я приведу улучшенную версию hypot_v2b, которая избегает работы с субнормальными числами.
inline float hypot_v2d(float x, float y)
{
x = std::fabs(x);
y = std::fabs(y);
float
min_ = x < y? x: y,
max_ = x < y? y: x,
mul, invmul;
if (max_ <= 0x1p-126f)
{
invmul = 0x1p-126f; // 0x1p-23 <= max_ <= 1
mul = 0x1p+126f; // 0x1p-23 <= min_ *
}
else if (max_ <= 0x1p-63f)
{
invmul = 0x1p-87f; // 0x1p-39 <= max_ <= 0x1p+24
mul = 0x1p+87f; // 0x1p-63 <= min_ *
}
else if (max_ <= 1.f)
{
invmul = 0x1p-24f; // 0x1p-39 <= max_ <= 0x1p+24
mul = 0x1p+24f; // 0x1p-63 <= min_ *
}
else if (max_ <= 0x1p+63f)
{
invmul = 0x1p+39f; // 0x1p-39 <= max_ <= 0x1p+24
mul = 0x1p-39f; // 0x1p-63 <= min_ *
}
else
{
invmul = 0x1p+102f; // 0x1p-38 <= max_ < 0x1p+26
mul = 0x1p-102f; // 0x1p-63 <= min_ *
}
max_ *= mul;
min_ *= mul;
if (max_ + min_ == max_)
return invmul * max_;
// * here.
return invmul * std::sqrt(max_* max_ + min_* min_);
}
Пусть есть два соседних числа в плавающей точке 
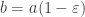
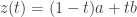


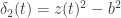

Заметим, что дискриминант обращается в нуль при 



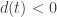

Аналогично, выбрав 

Теперь воспользуемся double для того, чтобы написать «reference»-версию с оценкой погрешности на основе hypot_v2d.
namespace float_bits
{
using ifloat = std::int32_t;
using ufloat = std::uint32_t;
static_assert(sizeof(ufloat) == sizeof(float));
inline ufloat to_bits(const float x)
{
return reinterpret_cast<const ufloat&>(x);
}
inline float to_float(const ufloat bits)
{
return reinterpret_cast<const float&>(bits);
}
inline bool of_same_sign(float a, float b)
{
return ((to_bits(a) ^ to_bits(b)) >> 31) == 0;
}
inline float bits_prev(float x)
{
return to_float(to_bits(x) - 1);
}
inline float bits_next(float x)
{
return to_float(to_bits(x) + 1);
}
inline ufloat ulp_distance(float a, float b)
{
const auto x = to_bits(a), y = to_bits(b);
return x < y? y - x: x - y;
}
}
inline float hypot_v2e(float x, float y)
{
x = std::fabs(x);
y = std::fabs(y);
float
min_ = x < y? x: y,
max_ = x < y? y: x,
mul, invmul;
if (max_ <= 0x1p-126f)
{
invmul = 0x1p-126f; // 0x1p-23 <= max_ <= 1
mul = 0x1p+126f; // 0x1p-23 <= min_
}
else if (max_ <= 0x1p-63f)
{
invmul = 0x1p-87f; // 0x1p-39 <= max_ <= 0x1p+24
mul = 0x1p+87f; // 0x1p-63 <= min_
}
else if (max_ <= 1.f)
{
invmul = 0x1p-24f; // 0x1p-39 <= max_ <= 0x1p+24
mul = 0x1p+24f; // 0x1p-63 <= min_
}
else if (max_ <= 0x1p+63f)
{
invmul = 0x1p+39f; // 0x1p-39 <= max_ <= 0x1p+24
mul = 0x1p-39f; // 0x1p-63 <= min_
}
else
{
invmul = 0x1p+102f; // 0x1p-38 <= max_ < 0x1p+26
mul = 0x1p-102f; // 0x1p-63 <= min_
}
max_ *= mul;
min_ *= mul;
if (max_ + min_ == max_)
return invmul * max_;
const double a = max_, b = min_, s = a*a + b*b;
const float
s_ = (float)s,
s0 = std::sqrt(s_),
s1 = float_bits::bits_prev(s0),
s2 = float_bits::bits_next(s0);
const double d0 = s0, d1 = s1, d2 = s2,
q0 = s - d0 * d0,
q1 = s - d1 * d1,
q2 = s - d2 * d2,
aq1 = std::fabs(q1),
aq2 = std::fabs(q2);
float res = s0;
if (aq1 < aq2)
{
const auto q1_0 = d1 - d0,
d = 2. * (q1 + q0) + q1_0 * q1_0;
if (d < 0. ||
(d == 0. && (float_bits::to_bits(s1) & 1) == 0))
res = s1;
}
else if (aq2 < aq1)
{
const auto q2_0 = d2 - d0,
d = 2. * (q2 + q0) + q2_0 * q2_0;
if (d > 0. ||
(d == 0. && (float_bits::to_bits(s2) & 1) == 0))
res = s2;
}
return invmul * res;
}
Результат hypot_v2e совпадает с результатом hypot_v3a почти везде: проверялись все x из набора { 3.16227766e-4f, 0.f, 1e-40f, 0x1p-126f — 0x1p-127f, 0x1p-126f, 1e-30f, 1e-20f, 1e-15f, 1e-6f, 1e-2f, 1.f, 1e+2f, 1e+6f, 1e+15f, 1e+20f, 1e+30f } для всех неотрицательных представимых чисел y — было найдено всего четыре пары (x, y), для которых результаты не совпали — три из них были приведены выше как «подозрительные».
Я написал аналог hypot_v2e, который оперирует только значениями float. Точное возведение в квадрат выполняется с помощью разрезания множителя числа на две 12-битные половинки (hi и lo). Затем вычисляются слагаемые hi*hi, lo*lo и 2*hi*lo. Результат — суммарно 50 отличающихся от hypot_v3a результатов (для того же перебора x-y), т.е. в среднем 1 ошибка на несколько сот миллионов пар (x, y). Тем не менее, не скажу, что такой результат мне особенно понравился. Хотелось бы почти полного совпадения с hypot_v2e или большей простоты кода…
Битовые операции I: битовые поля, степень двойки
Введение
Решил выложить накопленный материал по реализации некоторых операций с помощью стандартных операторов C. Планируется три части. Данный материал довольно легко найти на английском языке, и некоторые ссылки на источники я здесь размещу.
Предполагается, что читатель осведомлён о том, что такое поразрядные операции, и какие из них доступны в стандартном C. Стандартные целочисленные типы заданной ширины определены в stdint.h (cstdint в C++, «int» в случае C++ можно заменить на bool). Тип «unsigned» используется, чтобы показать отсутствие конкретных требований по разрядности параметра.
Так как во многих случаях описанные операции поддерживаются современными процессорами непосредственно, компиляторы предоставляют реализующие их специальные нестандартные функции («intrinsics» или «builtins»). Если целевой процессор поддерживает нужные команды, то при использовании интринсиков компилятор будет транслировать код в эти команды. К сожалению, не всегда гарантируется автоматическая подмена неподдерживаемых команд программными реализациями, поэтому при написании кроссплатформенного кода могут понадобиться собственные «заменители» для общего случая. Да и не всегда хочется отягощать код использованием интринсиков.
Простейшие манипуляции
Проверить значение заданного бита
Данное действие выполнить весьма просто: нужно установить бит с заданным номером, что легко достигается с помощью операции сдвига влево, и использовать полученное значение как маску.
inline int test_bit(unsigned word, unsigned bit)
{
return (word & (1u << bit)) != 0;
}
Ассемблерные аналоги x86: BT.
Изменить значение заданного бита
Следующие четыре функции возвращают новое значение слова (с изменённым битом в заданной позиции):
// Установить заданный бит
inline unsigned set_bit(unsigned word, unsigned bit)
{
return word | (1u << bit);
}
// Сбросить заданный бит
inline unsigned reset_bit(unsigned word, unsigned bit)
{
return word & ~(1u << bit);
}
// Поменять значение заданного бита на противоположное
inline unsigned toggle_bit(unsigned word, unsigned bit)
{
return word ^ (1u << bit);
}
// Установить заданный бит в заданное значение
inline unsigned set_bit(
unsigned word, unsigned bit, int value)
{
unsigned mask = 1u << bit;
return (word & ~mask) | (value? mask: 0);
}
Ассемблерные аналоги x86: BTS, BTR, BTC.
Извлечь битовое поле
Итак, операцией поразрядного сдвига влево можно установить бит в заданной позиции. Если теперь вычесть единицу, то получим битовую строку, в которой установлены все биты в позициях правее ранее установленного бита.
unsigned mask = (1u << bits) - 1;
Теперь можно сдвинуть полученную таким образом маску влево, чтобы установленные биты совпали с битами, стоящими в желаемых позициях (битовым полем). Под «битовым полем» в данном примере понимается непрерывный фрагмент машинного слова (например, все биты с 5-го по 10-й включительно).
Пусть задан номер начального бита, принадлежащего битовому полю (start), и количество бит, входящих в битовое поле (length; соответственно, все биты с 5-го по 10-й включительно: start = 5, length = 6). Тогда извлечь значение битового поля в виде беззнакового целого можно следующей функцией:
inline unsigned get_bitfield(
unsigned word, unsigned start, unsigned length)
{
return (word >> start) & ((1u << length) - 1);
}
Ассемблерные аналоги x86: BEXTR (BMI).
Установить значение битового поля
Обратная к предыдущей задача: требуется записать определённые значения бит в заданное битовое поле. Это можно сделать следующим образом (функция возвращает новое значение машинного слова):
inline unsigned set_bitfield
(
unsigned word, // Исходное значение
unsigned start, // Номер младшего бита поля
unsigned length, // Длина поля
unsigned value // Новое значение поля
)
{
unsigned mask = (1u << length) - 1;
return (word & ~(mask << start))
| ((value & mask) << start);
}
Наложение маски на value можно убрать, если гарантируется, что value не выходит за пределы диапазона значений битового поля (т.е. value ∈ [0, 2length-1]).
Совместить два значения
Изменение значения битового поля является частным случаем поразрядного совмещения (смешивания) значений. Пусть дана маска (mask), каждый бит которой равен 0, если значение соответствующего разряда результата следует взять из первой бит-строки (a), и 1, если значение разряда следует взять из второй бит-строки (b). Тогда выполнить операцию совмещения достаточно легко:
inline unsigned bit_blend(
unsigned mask, unsigned a, unsigned b)
{
return (a & ~mask) | (b & mask);
}
Степень двойки
Проверить, является ли число степенью двойки
Степень двойки в двоичной системе имеет вид 0..010…0 (только один бит установлен). Поэтому при вычитании единицы получаем 0..001…1, т.е. только в случае степени двойки выполняется условие нулевого пересечения числа с самим собой, уменьшенным на единицу. Итак,
inline int is_pow2(unsigned word)
{
return word & (word - 1) == 0;
}
Ряд подобных простых комбинаций, которые могут использоваться как строительные кубики, был введён в систему команд x86 в составе набора BMI.
Вычислить ближайшее сверху кратное заданной степени двойки
Пусть заданы натуральные числа P = 2p и число X. Необходимо вычислить наименьшее число N такое, что N ≥ X и N = nP для некоторого натурального n.
Метод вычисления. В случае, если X mod P не ноль, то добавление к X максимального остатка (P – 1) даёт перенос бита в разряд p, а если X mod P — ноль, то не даёт. Таким образом, если обнулить младшие p бит суммы (X + (P – 1)), то получим искомое: N = (X + (P – 1)) & ~(P – 1).
inline unsigned round_up_to_pow2(unsigned x, unsigned pow2)
{
unsigned pow2m1 = pow2 - 1;
// pow2 обязано быть степенью двойки
assert((pow2 & pow2m1) == 0);
return (x + pow2m1) & ~pow2m1;
}
Вычислить ближайшую сверху степень двойки
Требуется вычислить число, равное степени двойки, не меньшей, чем заданное натуральное число. Данную операцию реализовать сложнее, чем предыдущие. Ниже приведена реализация для 32-битного числа (позаимствовано отсюда).
inline uint32_t round_up_to_pow2(uint32_t x)
{
--x;
x |= x >> 1; // Группа наложений-сдвигов эффективно
x |= x >> 2; // заменяет линейную последовательность вида
x |= x >> 4; // x |= x >> 1; x |= x >> 2; x |= x >> 3; ...
x |= x >> 8; // x |= x >> 31;
x |= x >> 16; // На каждое удвоение разрядности достаточно
return x + 1; // добавлять одну такую строчку.
}
Впрочем, если имеется эффективная реализация функции leading_zero_bits, подсчитывающей количество идущих подряд старших нулей (можно реализовать её на основе команд x86 BSR или (ABM/BMI) LZCNT, в дальнейшем я планирую привести реализацию на основе стандартных операций), то можно использовать её:
inline unsigned round_up_to_pow2(unsigned x)
{
unsigned not_pow2 = (x & (x - 1)) != 0;
return 1u << (32 - (leading_zero_bits(x) + not_pow2));
}
