Эксперименты с hypot II
Небольшое дополнение к предыдущему посту. Ввиду низкого быстродействия frexp/ldexp может быть разумно заменить их на выбор множителя (степени двойки) банальными if-else.
inline float hypot_v2b(float x, float y)
{
x = std::fabs(x);
y = std::fabs(y);
float
min_ = x < y? x: y,
max_ = x < y? y: x,
mul, invmul;
if (max_ <= 0x1p-126f)
{
invmul = 0x1p-126f;
mul = 0x1p+126f;
}
else if (max_ <= 0x1p-63f)
{
invmul = 0x1p-63f;
mul = 0x1p+63f;
}
else if (max_ <= 1.f)
{
invmul = 1.f;
mul = 1.f;
}
else if (max_ <= 0x1p+63f)
{
invmul = 0x1p+63f;
mul = 0x1p-63f;
}
else
{
invmul = 0x1p+126f;
mul = 0x1p-126f;
}
max_ *= mul;
min_ *= mul;
return invmul * std::sqrt(max_* max_ + min_* min_);
}
Данный код предотвращает некорректное переполнение и исчезновение и обеспечивает погрешность 1 ULP. Конечно, гребёнка if-ов сказывается на скорости работы — у меня получилось, что hypot_v2b примерно втрое медленнее hypot_v1 (но всё же в десять раз быстрее hypot_v2a). Эта оценка довольно условна, так как скорость исполнения ветвлений зависит от множества факторов.
Аналогичный способ можно применить для замены frexp/ldexp при вычислении произведений. Например, если произведение получилось меньше по абсолютной величине наименьшего положительного нормального числа, то пересчитать его, предварительно домножив на 0x1p+63f; если произведение стало бесконечным (переполнение) или приблизилось по величине к наибольшему представимому числу, то пересчитать его, домножив на 0x1p-63f.
Эксперименты с hypot
В стандартной библиотеке математических функций C++ (унаследованной от C) имеется функция hypot(x, y), возвращающая евклидову длину вектора (x, y).
Зачем особая функция, если можно просто определить «в лоб»?
inline float hypot_v1(float x, float y)
{
return std::sqrt(x * x + y * y);
}
(Здесь я использую float и только float по причине, о которой будет сказано ниже.)
Причин может быть несколько:
- Гарантировать отсутствие переполнения (из-за возведения в квадрат большого числа или сложения больших чисел) в случае, когда конечный результат (длина) представим.
- Гарантировать отсутствие влияния исчезновения (из-за возведения в квадрат слишком маленького числа) на результат. В частности, в случае, когда один из аргументов x, y есть нуль, а другой — число, hypot(x, y) должен возвращать модуль другого аргумента, даже если это субнормальное число.
- Обеспечивать погрешность лучше 1 ULP.
Легко показать, что hypot_v1 не удовлетворяет всем этим пунктам. Экспериментально установлено, что погрешность hypot_v1 на основной части диапазона, где не возникает ситуация вредоносного переполнения или исчезновения составляет 1 ULP (проверка для y из набора { 0.f, 1e-40f, 1e-30f, 1e-20f, 1e-15f, 1e-6f, 1e-2f, 1.f, 1e+2f, 1e+6f, 1e+15f, 1e+20f, 1e+30f } и для всех возможных значений x).
В активе hypot_v1 сравнительно большая скорость вычисления (у меня получилось, что она примерно в 10 раз быстрее, чем стандартная hypot на g++ -O3).
Можно ли получить какой-то иной компромисс в плане скорости и качества? В Википедии можно наблюдать следующий вариант (на момент написания). Ниже дан исправленный код:
inline float hypot_v2(float x, float y)
{
x = std::fabs(x);
y = std::fabs(y);
const float
min_ = x < y? x: y,
max_ = x < y? y: x;
if (max_ == 0.f || std::isinf(max_))
return max_;
const float q = min_ / max_;
return max_ * std::sqrt(1.f + q*q);
}
Хорош ли этот код? Он страхует нас от патологического переполнения и исчезновения. Что можно сказать о его скорости? В моём эксперименте получилось, что hypot_v2 примерно вдвое медленнее hypot_v1, что можно считать приемлемым. Что можно сказать о погрешности? Экспериментально получено максимальное значение 2 ULP.
В стремлении убрать операции, вносящие погрешность, я написал иной вариант, использующий вынесение степеней двойки:
inline float hypot_v2a(float x, float y)
{
x = std::fabs(x);
y = std::fabs(y);
if (x == 0.f)
return y;
if (y == 0.f)
return x;
float
min_ = x < y? x: y,
max_ = x < y? y: x;
int min_e, max_e;
min_ = std::frexp(min_, &min_e);
max_ = std::frexp(max_, &max_e);
min_ *= min_;
max_ *= max_;
return std::ldexp(
std::sqrt(std::ldexp(min_, 2*(min_e - max_e)) + max_),
max_e);
}
Этот вариант действительно обеспечивает погрешность <= 1 ULP (экспериментально). К сожалению, этот код в моём случае работал втрое медленнее стандартной hypot. (Что может говорить о потенциально низком быстродействии кода предложенного мной для перемножения массивов чисел.)
Теперь следует прояснить вопрос об экспериментальном вычислении погрешности. Так как используются числа float (IEEE-754 binary32, 23 двоичных разряда после запятой), и доступны числа double (IEEE-754 binary64, 52 двоичных разряда после запятой), то нетрудно организовать вычисление ближайшего к истинной величине значения в формате float, попросту выполнив вычисление с точностью double и округлив затем результат до float:
inline float hypot_v3(float x, float y)
{
const double x_ = x, y_ = y;
return (float)std::sqrt(x_ * x_ + y_ * y_);
}
Кстати, этот вариант также не страдает от переполнения и исчезновения и вычисляется лишь вдвое медленнее hypot_v1, обеспечивая погрешность <= 0.5 ULP. Он плох тем, что не масштабируется на double (хотя можно задействовать софтовое вычисление с точностью IEEE-754 binary128, заплатив за это резким падением производительности), зато очень удобен для определения качества других вариантов, включая стандартную hypot.
В случае g++ результат hypot везде совпал с результатом hypot_v3 (т.е. точность <= 0.5 ULP стандартной hypot обеспечена). Интересно, что для её вычисления используется древний (1993г.) код от Sun Microsystems, довольно зубодробительного вида.
В принципе, альтернативой hypot и hypot_v1 может стать их гибрид, использующий hypot_v1 там, где она работает хорошо (с погрешностью 1 ULP), а в остальных случаях (предположительно, редких) вызывающий hypot:
inline float hypot_v4(float x, float y)
{
x = std::fabs(x);
y = std::fabs(y);
if (1e-19f <= x && x <= 1e+19f &&
1e-19f <= y && y <= 1e+19f)
return std::sqrt(x*x + y*y);
return std::hypot(x, y);
}
Такой код способен работать со скоростью, в среднем близкой к скорости hypot_v1.
Борьба с переполнением и исчезновением при вычислении произведений
Пусть дан массив чисел с плавающей запятой, требуется найти произведение.
double product(const double x[], size_t n)
{
double p = 1.;
for (size_t i = 0; i < n; ++i)
p *= x[i];
return p;
}
Какие недостатки у приведённого выше очевидного решения?
Из трёх компиляторов (g++ 7.1, clang 4.0, icc 17.0) векторизацию данного цикла (параметры -O3 -mavx2) выполнил только icc, что лишь подтверждает известный тезис о том, что icc порой действует чересчур агрессивно: операция умножения в плавающей точке не ассоциативна.
Для любителей обобщённого кода можно записать то же самое, но для «любых чисел»:
#include <iterator>
#include <functional>
#include <numeric>
template <class It>
auto product(It from, It to)
{
return std::accumulate(from, to,
typename std::iterator_traits<It>::value_type(1),
std::multiplies<>{});
}
Потенциальная проблема прямого «наивного» перемножения заключается в возможном переполнении или исчезновении промежуточного результата, в то время как реальный окончательный результат был бы представим в диапазоне используемых чисел (например, перемножаем много больших чисел, затем много маленьких, или наоборот).
Одно из возможных решений — складывать логарифмы, затем сумму возвести в степень:
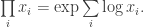
Данный способ, вероятно, лучше подходит для работы с числами с фиксированной запятой (на практике, естественно, лучше использовать логарифм и возведение в степень по основанию 2).
В случае плавающей запятой на основе средств стандартной библиотеки C доступен способ получше: комбинация frexp и ldexp.
Лучше он как с точки зрения скорости (по сути это просто битовые операции над представлением числа), так и с точки зрения точности (не привносит дополнительной погрешности по сравнению с обычным произведением).
#include <cmath>
#include <iterator>
template <class It, class NT>
NT product(It from, It to, NT first)
{
using std::frexp;
using std::ldexp;
int e = 0;
NT p = frexp(first, &e);
for (int e2 = 0; from != to; ++from)
{
p = frexp(p * *from, &e2);
e += e2;
}
return ldexp(p, e);
}
template <class It> inline
auto product(It from, It to)
{
return product(from, to,
typename std::iterator_traits<It>::value_type(1));
}
Или то же самое в виде функтора:
template <class NT, class ET = long>
class Frexp_ldexp_product
{
NT p;
ET e;
public:
using Number = NT;
using Exponent = ET;
explicit Frexp_ldexp_product(Number first = Number(1))
{
using std::frexp;
int first_e = 0;
p = frexp(first, &first_e);
e = first_e;
}
Number operator()() const
{
using std::ldexp;
return ldexp(p, e);
}
void operator()(Number next)
{
using std::frexp;
int next_e = 0;
p = frexp(p * next, &next_e);
e += next_e;
}
Number significand() const
{
return p;
}
Exponent exponent() const
{
return e;
}
};
// Пример использования: при обработке диапазона.
template <class It, class NT>
NT product(It from, It to, NT first)
{
return std::for_each(from, to,
Frexp_ldexp_product<NT>{first})();
}
Функтор удобнее, если значения в произведении генерируются на ходу, а не лежат в памяти. Кроме того, есть возможность получить отдельно мантиссу ∈ (0.5, 1] и порядок, даже если результирующее произведение не помещается в диапазон используемого типа чисел с плавающей точкой.
Напоследок хочется отметить, что если проблема переполнения/исчезновения снята, то рост накопленной погрешности остановить не так просто. Хотя результат произведения зависит от порядка, оценка относительной погрешности от порядка выполнения операций не зависит:

В каком порядке не перемножай, всё равно получится относительная погрешность ne, где n — число сомножителей, e — половина «эпсилона» (ULP).
